Text mining – or simply having fun
Published: March 13, 2026
Artificial intelligence (AI) is not only on everyone's lips, it's cool and fun.
We simply put lots of data into a suitably configured computer, start the analysis and get unexpected correlations visualized in the most beautiful colors.
"Have a lot of fun!" is the motto of the Linux veterans from (now)openSUSE. And because Linux distributions now come with everything an AI fan could wish for out of the box, this also works here.
Text mining - not that easy
But if it really is that simple, why do we keep being approached by customers whohave "tried everything" , who"no longer believe" that their problem can be solved and who regularly make us break out in a sweat with their questions?
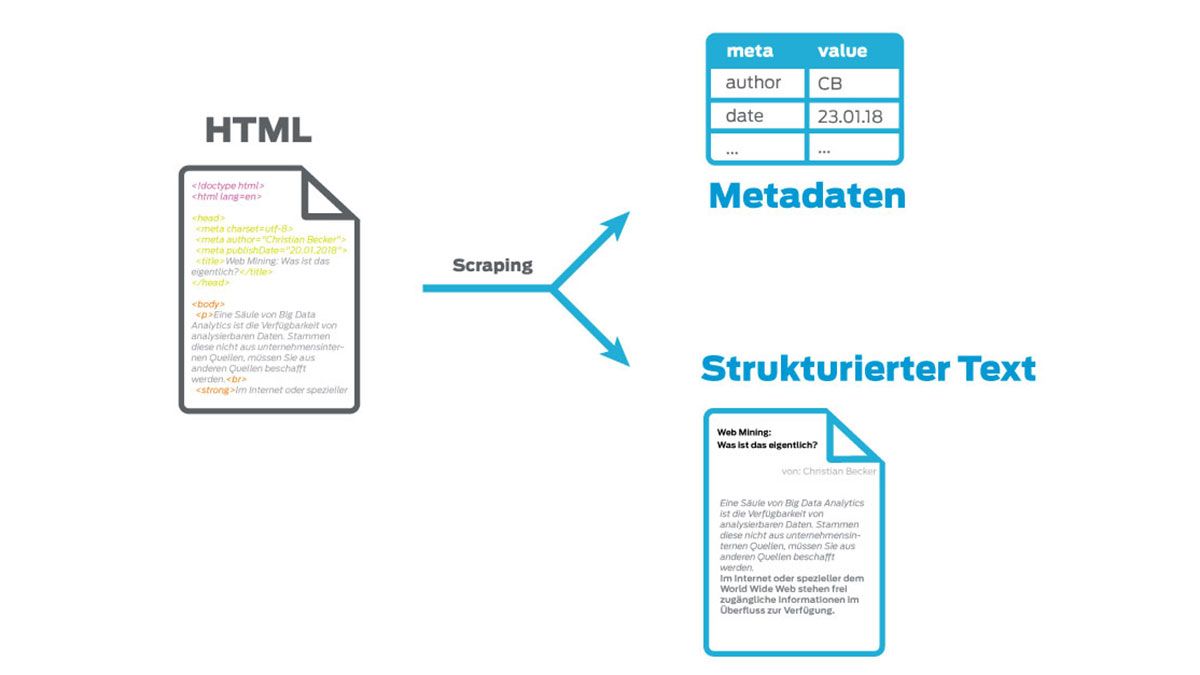
Wikipedia leads to a clue; a misunderstanding that we experience again and again and which is so beautifully summed up there. In the very nicearticle on text mining, it says under several steps for data preparation of texts:
"Proper names for persons, places, of companies, states, etc. must be recognized because they have a different role in constituting the meaning of the text thangeneric nouns."
Typical questions?
What is irritating about this? We need to expand a little on this: The typical use case we deal with atEmpolis is that our customers have a very specific question that could probably be answered from texts available somewhere. However, the number of texts is so large that the effort required to answer them is no longer economically viable.
Fictitious examples/questions
Which competitors do we have that we don't even know yet because they have only just been founded and only appear in listings when they have long since conquered their market with an ingenious new idea?
How will theEthereum price develop in the next 60 minutes, because the trader asking the question would need 120 minutes to manually evaluate all the sources of information relevant to the forecast?
Generic nouns?
To answer such questions, we find most helpful information in texts. A start-up as a new competitor may not yet have a product or even its first customer, but it does have a website through which the company can be found.
The price development of cryptocurrencies is still so fragile that individual Twitter messages or government statements can lead to incredible price jumps within minutes, which could not even have been anticipated from the short, medium and long-term price trends.
However, in order to find the right data and gain the right information, we need precisely what Wikipedia brushes aside asgeneric nouns.
If you are looking for new competitors, you obviously need to recognize proper names of companies - and that's easy. You will find countless software libraries and models that do this and recognize every Daimler, every Chrysler and every Mercedes (a few even differentiate between cars of theMercedes brand and people with the same name).
But we are looking for companies that are brand new and whose names have not yet been labeled hundreds of times in their training corpus so that the AI knows thatMedibloc or Zigzag are company names .
This is where the fun ends for manydata scientists - for the passionatetext miner, this is exactly where the fun begins .
The fun of text mining
Let's stick with the start-up example: we have to do a bit of work to transform the generic nouns"Medibloc " and"Zigzag " into companies. For example, we can find the following information about "Medibloc" on the web:
Perfect! If we don't even search for company names, but for the (generic) noun "startup", we find a lead to this text - and if we add the variants "start-up", "start up", "new company" and a few others to the term "startup", we also find similar patterns. At least two questions still need to be answered:
Does the "startup" actually refer to a company and if so, what is its name?
Is the company mentioned interesting in the current context - i.e. does my customer want to know?
The first part can actually be answered semi-generically: We are looking for a noun to which the noun "startup" we have already found refers. Dependency parsers can be used for such analyses, which display the relationship between the individual sentence components. For the sentence mentioned above, for example,displaCy providesa well-structured representation of the relationships. Alternatively, the same analysis can also be carried out using linguistic rule languages such as Apache Ruta. In both ways, we arrive at the noun "Medibloc", which we then know is a "startup".
In the same way, we can also search for adjectives or adverbs that describe our "startup" in more detail. In this case, we find the property "medical logistics blockchain", which is assigned to the "startup", and we can use the verb "create" to derive the targeted product ("record database on blockchain") in the next step.
Finally, we can separate the wheat from the chaff by using a small model to describe all the topics that a start-up company of interest to us should deal with. So we take a lot of "generic nouns" again and use them to describe our areas of interest. Our traders are interested in "blockchain", "ethereum", "bitcoin" etc., my colleagues from the industrial analytics sector are interested in "predictive maintenance"," IoT", "anticipatory maintenance" etc., and we define additional classes for other users as required.
Then we end up with a generic mechanism to recognize mentioned start-ups in texts and for each domain we are interested in; a small model to determine the relevant domains.
Until a very reliable recognition rate is achieved, there is usually still some work to be done to collect possible patterns and create the analysis rules and models. But even with very simple means, much more information can be obtained than through manual searches. And any helpful information that we didn't have before increases the fun factor immensely.
However, this can only work if we successively take care of giving meaning to the "generic nouns" (and adjectives and adverbs and prepositions and so on). Or to put it another way: there is no such thing as a generic noun. There are things we want to know and things we don't care about. We'll deal with the former now, but not the latter.
Better data and applications through text analytics
AI is cool, we claimed, and working with AI is fun. One of the main reasons for this is that a large number of libraries and methods are available that can quickly produce good results. However, if our data is still in unstructured text - as is all too often the case - then we first have to make it available to these data analytics tools. Many data scientists find this so tedious that they prefer to skip this step, live with poorer data or not even tackle use cases with such requirements.
I would like it better if data scientists were to involve text analytics experts much more frequently in order to achieve better data and better applications more quickly together, if both were to contribute what they each enjoy most and if, in this way, more and more text analytics requirements could be implemented as easily in future as is already the case for other areas of AI.
The Perfect Solution for you
We look forward to a non-binding consultation and will be happy to work with you to determine which product provides the greatest value for your needs. Let’s make better decisions together, faster.