
Wie viele Daten benötigt ein NLP-Algorithmus?
Zurück zum BlogNatural Language Processing-Systeme – darunter auch die von Empolis – funktionieren out of the box, um Textdaten aus der klinischen Routine zu analysieren. Häufig werden jedoch spezielle Daten eines Krankenhauses, eines Instituts, einer Abteilung – erstellt von speziellen Personengruppen mit eigenem Fachvokabular – analysiert.
Hier werden wir häufig gefragt, wie viele Trainings- und Testdaten notwendig sind, um eine hohe Güte der Analysen sicherzustellen. Die einfache Antwort „Geben Sie uns so viele Daten wie möglich, wir nutzen dann davon 90 Prozent zum Training und 10 Prozent zum Testen“ ist nicht hilfreich.
Warum macht man es sich mit dieser Antwort zu einfach?
Typischerweise möchte man so wenig Daten wie möglich und so viele wie nötig übermitteln (z. B. aus Datenschutzgründen).
Wie viele Daten man zum Training benötigt, lässt sich niemals vorher eindeutig sagen, da dies auf den Use Case ankommt.
10 Prozent der gesamten verfügbaren Daten zum Testen können sowohl zu viel als auch zu wenig sein.
In diesem Blogartikel wollen wir eine etwas präzisere Antwort erarbeiten: einmal analytisch, einmal empirisch.
Die Idee der Konfidenzintervalle
Was steckt hinter den Konfidenzintervallen?
Letztendlich die Information, wie sicher man sich sein kann, ob eine Statistik auf einem zufälligen „Sample“ auch auf dem Gesamtdatensatz gilt.
In unserem Fall wollen wir herausfinden, ob die Güte unseres NLP-Algorithmus bei der Annotation eines Textes mit einem Konzept, gezeigt auf einem zufälligen „Sample“, auch auf dem Gesamtdatensatz gilt.
Die Güte „p“ eines NLP-Algorithmus beschreibt, wie häufig er statistisch richtig liegt (häufig als Genauigkeit, Trefferwahrscheinlichkeit, Trefferquote oder andere ausgewählte Metriken). Die Samplegröße „n“ beschreibt die Anzahl an Versuchen mit zufälligen Beispielen aus dem Gesamtdatensatz.
Die Frage ist: Bei Güte „p“ und Samplegröße „n“ über welchem minimalen und unter welchem maximalen Wert um die gezeigte Güte liegt mit hoher Wahrscheinlichkeit (typischerweise 95 Prozent) die tatsächliche Güte auf dem Gesamtdatensatz?
Die analytische Berechnung
Es gibt verschiedene Methoden, um ein Konfidenzintervall zu berechnen. Die Methoden unterscheiden sich zum Beispiel in den Annahmen an die Daten.
In unserem Fall können wir zum Beispiel von einer Binomialverteilung ausgehen, bei der ein Experiment eine bestimmte Anzahl durchgeführt wird, jeweils mit dem Ergebnis „erfolgreich bzw. Annotation korrekt“ oder “nicht erfolgreich bzw. Annotation inkorrekt“.
Um nun ein Binomial Confidence Interval zu berechnen, kann man zudem weitere Annahmen treffen.
Wenn zum Beispiel von einer Normalverteilung ausgegangen wird (Normalverteilungs-Approximation), vereinfacht sich die Berechnung, allerdings ist diese Annahme häufig zu optimistisch (außerdem gibt es Probleme am Rand der Wahrscheinlichkeit sehr nah bei 1).
Die Methode Clopper–Pearson Intervall ist dagegen möglichst „exakt“ und nutzt diese Annahmen nicht, ist allerdings manchmal ein wenig „zu vorsichtig“ bzw. konservativ.
Ein guter Kompromiss ist das Wilson Score Intervall. Diese Methode wird auch in wissenschaftlichen Arbeiten zur Evaluation von NLP-Systemen genutzt, z. B. siehe Sippo et al. 2013.
Berechnung des Wilson Score Konfidenzintervalls
In der Literatur gibt es mehrere Beispiele, um das Wilson Score Konfidenzintervall zu berechnen (z. B. mit R oder mit Python). Wir nutzen eine Methode mit Python aus Stackoverflow und haben sie leicht angepasst:
import numpy as np
import scipy.stats
import math
def binconf(p, n, c=0.95):
if n == 0.0: return (0.0, 1.0)
# z = normcdfi(1 – 0.5 * (1-c))
# Advise by philipp mildenberger
z = scipy.stats.norm.ppf(1 – 0.5 * (1-c))
a1 = 1.0 / (1.0 + z * z / n)
a2 = p + z * z / (2 * n)
a3 = z * math.sqrt(p * (1-p) / n + z * z / (4 * n * n))
return (a1 * (a2 – a3), a1 * (a2 + a3))
Was ist die Durchschnittsabweichung nach unten oder oben?
def compAvg(p, res0, res1):
print(„Lower“)
print(p – res0)
print(„Upper“)
print(res1 – p)
print(„Average“)
print((p – res0+res1 – p)/2)
Setzen wir also unsere Parameter:
n = 200
p = 0.85
result = binconf(p,n)
print(result)
compAvg(p, result[0], result[1])
(0.7939442071583332, 0.89286406437758)
Lower
0.05605579284166673
Upper
0.04286406437758006
Average
0.049459928609623394
Das heißt vereinfacht ausgedrückt, die Güte ist 85 Prozent +- 5 Prozent in 95 Prozent der Fälle, falls ich auf dem „Sample“ eine Güte von 0.85 oder besser zeige. Falls ich anstatt 200 nur 100 Beispiele ins Sample aufnehme, ist die mögliche Ungenauigkeit deutlich größer, 7 Prozent:
n = 100
p = 0.85
result = binconf(p,n)
print(result)
compAvg(p, result[0], result[1])
(0.7671644040916763, 0.9069401471634336)
Lower
0.08283559590832368
Upper
0.05694014716343365
Average
0.06988787153587867
Noch schlimmer sähe das aus, wenn man auf 100 Fällen nur eine Güte von 0.75 zeigen kann: n = 100
p = 0.75
result = binconf(p,n)
print(result)
compAvg(p, result[0], result[1])
(0.656955364519384, 0.8245478863771232)
Lower
0.09304463548061603
Upper
0.07454788637712317
Average
0.0837962609288696
Jetzt möchte ich das noch empirisch zeigen.
Die empirische Berechnung
Dazu führe ich n-mal ein Zufallsexperiment durch und prüfe jeweils, ob es erfolgreich war oder nicht:
from matplotlib import pyplot
def experiment(n,p):
# we draw a sample result
sample_population_result = []
# this result has same distribution as the overall population result
sample_population = np.random.rand(n)
for i in sample_population:
result = 0.0
# the experiment is successful with p %
if i <= p:
result = 1.0
sample_population_result.append(result)
# Question is, how probable is it, that this was created by chance?
# According to the Wilson Score interval, in 95% this will be in the
range of (0.850620891970041, 0.934316655935257)
return sum(sample_population_result)/n
Dann lasse ich mir visualisieren, wie häufig im Durchschnitt die Experimente erfolgreich waren oder nicht, wenn ich sie sehr häufig durchführe: def plot(n,p):
experiments_mean = []
number_experiments = 100000
for x in range(number_experiments):
experiments_mean.append(experiment(n,p))
binwidth = 1
pyplot.hist(experiments_mean, bins=np.arange(0.5,1,0.01), density=1) # density=1, stacked=True, cumulative=False, alpha=1
pyplot.axis([0.5, 1, 0, 20])
pyplot.grid(True)
pyplot.show()
# confidence intervals
alpha = 0.95
p = ((1.0-alpha)/2.0) * 100
lower = max(0.0, np.percentile(experiments_mean, p))
p = (alpha+((1.0-alpha)/2.0)) * 100
upper = min(1.0, np.percentile(experiments_mean, p))
print(‘%.1f confidence interval %.1f%% and %.1f%%’ % (alpha*100, lower*100, upper*100))
Dazu nehme ich zunächst einmal an, ich habe 200 Beispiele und zeige darauf eine Güte von 0.85:
# In our sample, how often are we correct?
p = 0.85
# How large is our sample?
n = 200
# overall_population_result average we do not know
plot(n,p)
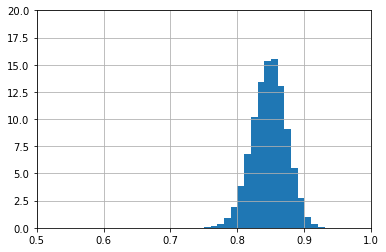
Bei 200 Beispielen liegt die Güte wieder am wahrscheinlichsten bei 85 % +- 5%
Schlechter sieht es aus, wenn man nur 100 Beispiele nimmt:
Bei 200 Beispielen liegt die Güte wieder am wahrscheinlichsten bei 85 % +- 5%
Schlechter sieht es aus, wenn man nur 100 Beispiele nimmt:
# In our sample, how often are we correct?
p = 0.85
# How large is our sample?
n = 100
# overall_population_result average we do not know
plot(n,p)
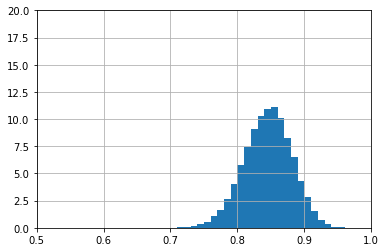
Das Histogramm ist deutlich flacher, die gezeigte Güte wurde mit höherer Wahrscheinlichkeit durch reinen Zufall erreicht und könnte auch einer Güte deutlich unter der gezeigten entsprechen.
Noch schlimmer sieht es aus, wenn nur eine Güte von 0.75 anvisiert wird, denn je niedriger die Güte, desto höher die Schwankungen:
# In our sample, how often are we correct?
p = 0.75
# How large is our sample?
n = 100
# overall_population_result average we do not know
plot(n,p)
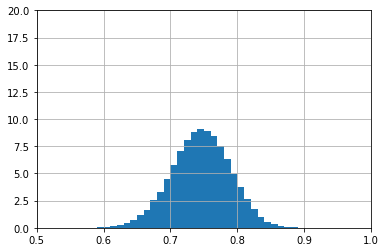
Die Take-Home-Message
Auf die Frage, „Wie viele Trainings- und Testdaten benötigt ein NLP-Algorithmus?“ ist es daher sinnvoller zu antworten:
Bei einer geplanten Güte von 0.85 sollten wir zumindest 200 zufällig ausgewählte Beispiele zum Testen nutzen, damit die Güte zu einer hohen Wahrscheinlichkeit auch auf dem Gesamtdatensatz gilt (nämlich mit 95 Prozent Wahrscheinlichkeit nur 5 Prozent davon abweicht).
Dieser Test wird zeigen, ob wir (weiter) trainieren müssen. Falls das Testergebnis verbessert werden muss, nutzen wir die Testdaten zum Trainieren und erstellen anschließend einen neuen Testdatensatz.
Diesbezüglich abschließend noch drei wichtige Tipps:
Die Testdaten sollten ganz zufällig aus dem Gesamtdatensatz herausgezogen werden. Jeder „Bias“ sorgt hierfür, dass die Güte auf dem Gesamtdatensatz anders aussehen würde und das Vertrauen in die Statistik deutlich geringer ausfallen muss. Auf diese Weise sind auch positive und negative Beispiele „stratifiziert“ im Sample enthalten.
Die Testdaten sollten ausschließlich zum Testen und nicht zum Training verwendet werden. Anderenfalls bringt man auch hier „Bias“ in das Modell, so dass man der Statistik in Bezug auf den Gesamtdatensatz nicht mehr vertrauen kann
Wenn Test- und Trainingsdaten manuell durch Annotation erstellt werden müssen, ist dies ein großer Aufwand. Daher wird stets nach Möglichkeiten gesucht, um die Anzahl an Daten weiter zu minimieren. Um den Rahmen dieses Blogartikels nicht zu sprengen, möchte ich hier Cross-Validation, Data Augmentation oder Semi-Supervision als Beispielmöglichkeiten nur kurz nennen.
Viel Erfolg in Ihren nächsten Data-Analytics-Projekten!
Danksagung
Vielen Dank an Philipp Mildenberger für die Mithilfe bei diesem Blogartikel.